Beautifulsoup으로 크롤링한 데이터를 장고 DB에 넣어보았습니다. 백엔드는 항상 어려우나 해결하는 즐거움이 있는 것 같습니다. 시간만 덜 걸리면 좋으려만 그래도 여러 삽질 끝에 얻는 지식은 너무 소중한 것 같습니다. 우선 코딩 전문입니다.
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
import ssl
from bs4 import BeautifulSoup
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "backend.settings")
import django
django.setup()
from api.models import Search_Recipe
def getRecipeCrawler(element):
baseUrl = 'https://haemukja.com/recipes?sort=rlv&name='
url = baseUrl + urllib.parse.quote_plus(element)
html = urllib.request.urlopen(url, context=ssl._create_unverified_context()).read()
soup = BeautifulSoup(html, 'html.parser')
result = []
i = 0
for anchor in soup.select('a.call_recipe > strong'):
print(anchor.get_text())
i += 1
recipe_obj = {
'recipe_ID': i,
'recipe_Name': anchor.get_text(),
'ingredient_Key': element
}
result.append(recipe_obj)
return result
# insert data into sqlite
if __name__=='__main__':
recipe_data = getRecipeCrawler("당근")
for item in recipe_data:
Search_Recipe(recipe_ID = item['recipe_ID'], recipe_Name = item['recipe_Name'], ingredient_Key = item['ingredient_Key']).save()
이 파일을 root 파일에 넣어 주시고 models.py에 연동해주시면 됩니다. 이 두 파일을 연동하는 역할을 해주는 코드는 다음과 같습니다.
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "backend.settings")
import django
django.setup()
# 여기가 models.py에서 설계한 모델을 가져오는 코드입니다
from api.models import Search_Recipe원하는 데이터를 다음과 같이 크롤링을 한 후,
baseUrl = 'https://haemukja.com/recipes?sort=rlv&name='
url = baseUrl + urllib.parse.quote_plus(element)
html = urllib.request.urlopen(url, context=ssl._create_unverified_context()).read()
soup = BeautifulSoup(html, 'html.parser')크롤링한 데이터를 리스트에 형식에 맞게 저장 후 리턴합니다. ingredient_Key는 검색할 재료가 들어가는 변수입니다.
result = []
i = 0
for anchor in soup.select('a.call_recipe > strong'):
print(anchor.get_text())
i += 1
recipe_obj = {
'recipe_ID': i,
'recipe_Name': anchor.get_text(),
'ingredient_Key': element
}
result.append(recipe_obj)
return result이후 이 리턴 값을 장고 ORM에 저장해주는 과정을 거쳐야 하는데 이는 다음과 같습니다.
# insert data into sqlite
if __name__=='__main__':
recipe_data = getRecipeCrawler("당근")
for item in recipe_data:
Search_Recipe(recipe_ID = item['recipe_ID'], recipe_Name = item['recipe_Name'], ingredient_Key = item['ingredient_Key']).save()꼭 if __name__=='__main__' 이 있어야 파이썬 내에서 실행할 수 있습니다. Search_Recipe는 앞서 import한 모델에서 설계한 데이터 구조에 .save()로 저장하는 것이죠. 설계한 모델은 다음과 같습니다.
# models.py
from django.db import models
# Create your models here.
class Search_Recipe(models.Model):
recipe_ID = models.IntegerField(primary_key = True)
recipe_Name = models.CharField(max_length=50)
ingredient_Key = models.CharField(max_length=50)
class Meta:
db_table = 'recipe'이렇게 크롤링을 설계하시면 파이썬 파일을 run 하셔야겠죠? 터미널에서 다음과 같이 파일을 실행합니다. 아래의 python은 본인의 버전에 맞게 넣어주시면 됩니다. 저는 python3라 아래와 같이 실행했습니다. 에러가 나지 않는다면 잘 저장된 것입니다.
$ python3 파일명.py저장된 데이터를 확인하려면 장고의 admin 페이지로 가시면 확인하실 수 있습니다. admin 페이지로 가려면 우선 superuser를 설정해주셔야 합니다. 터미널에 다음과 같이 작성합니다.
$ python3 manage.py createsuperuser이후 원하시는 아이디와 비번을 설정해 주신 후 서버를 연결합니다.
python3 manage.py runserver
아래와 같이 로그인 해주시고..

설계한 데이터가 보이네요, 저기 Search_recipes 입니다
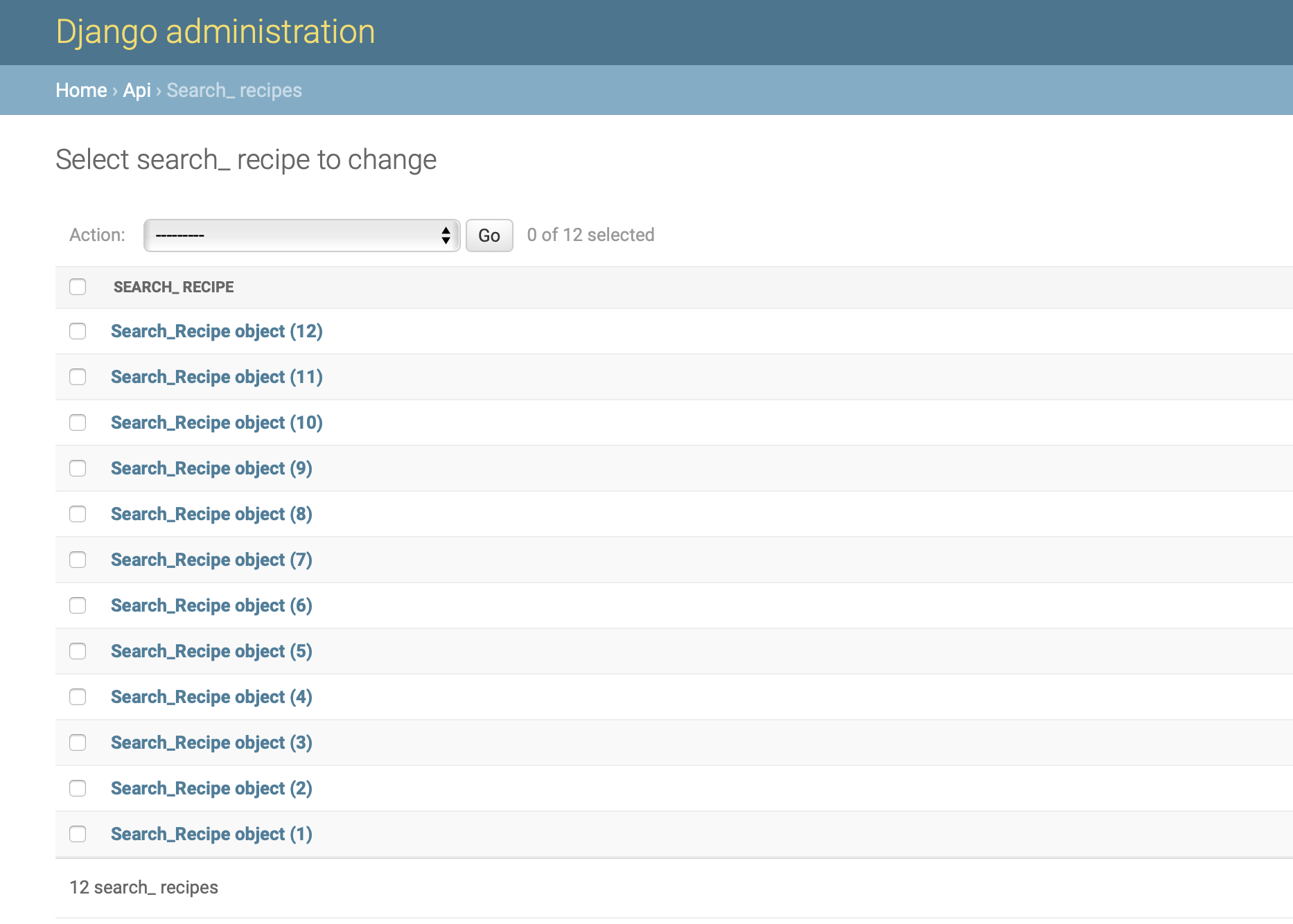
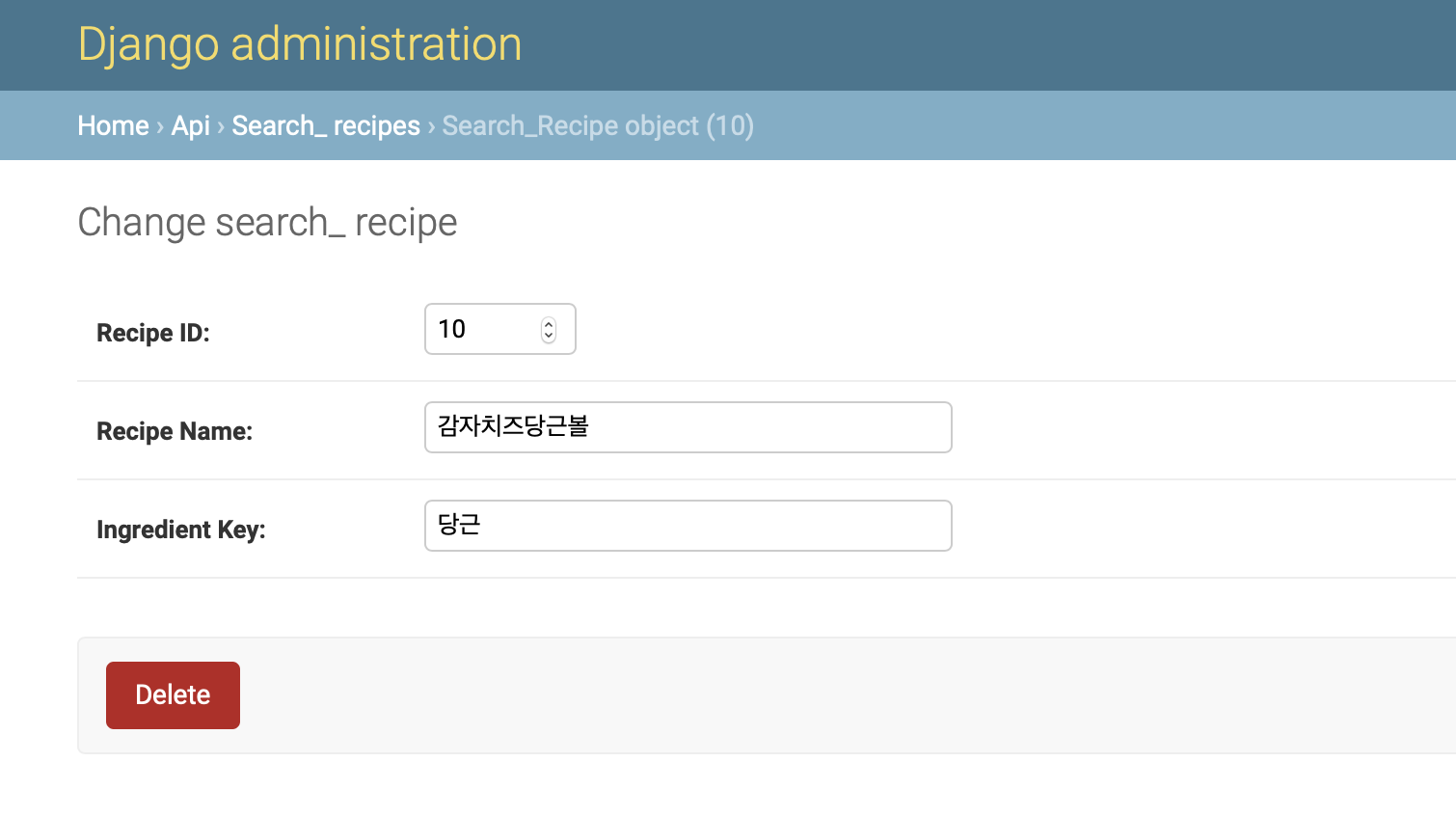
잘 저장 되었군요!! 그럼 이제 이 저장한 데이터를 리액트로 띄울 일만 남았습니다! 아래는 파일 위치입니다 혹시 파이썬 파일 위치 궁금하실까 싶어 첨부합니다 위의 크롤링 파일 명은 getRecipeCrawler.py고 맨 밑에 있습니다.
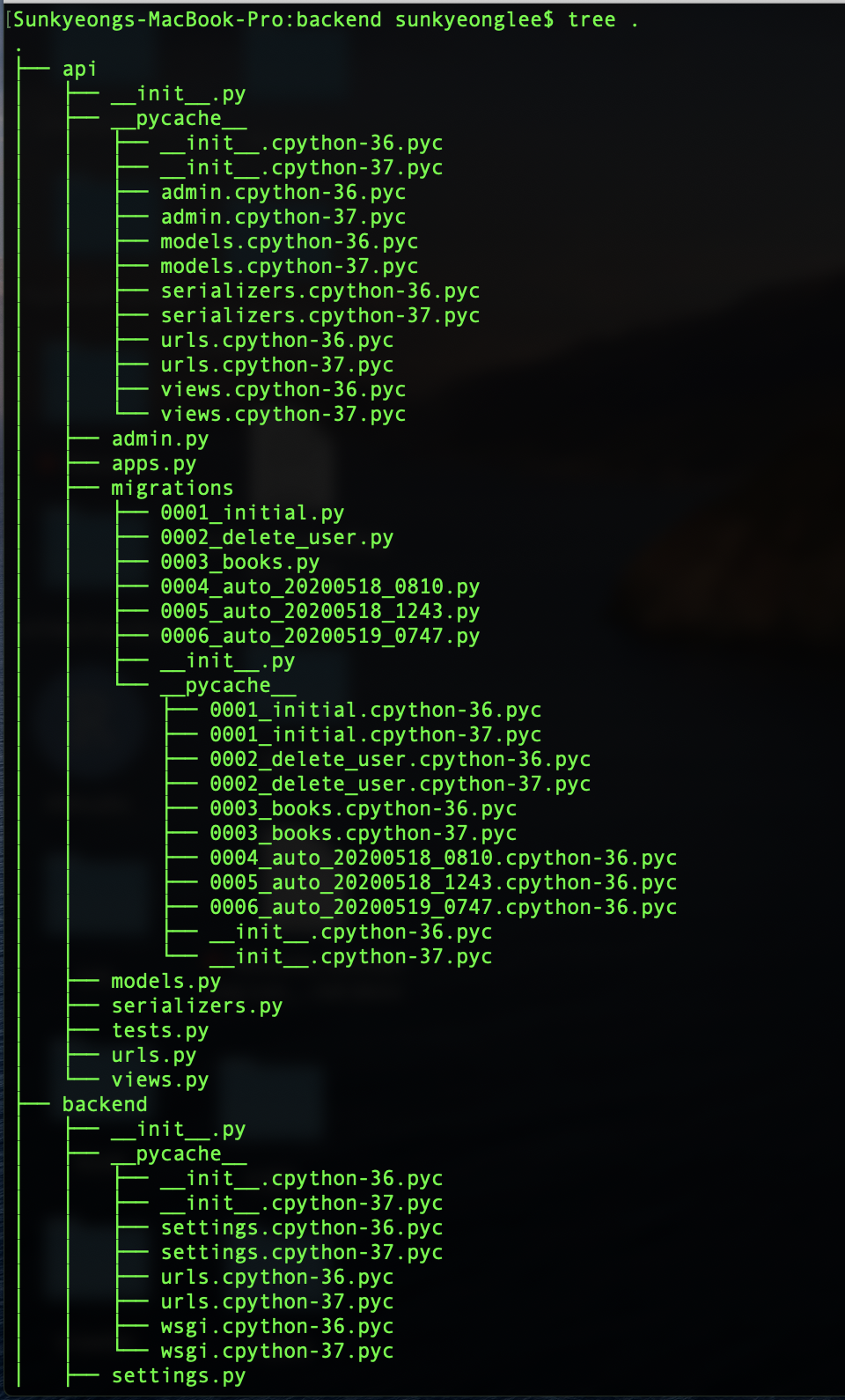

모두 해피코딩! : D
'개발 기록 (~2023)' 카테고리의 다른 글
| K-fold Cross Validation K-겹 교차 검증 (0) | 2020.06.18 |
|---|---|
| 분석) Missingno 설치 command (0) | 2020.06.04 |
| 크롤링) 파이썬이 한글을 읽지 못할때 (0) | 2020.05.20 |
| Django project) sqlite migration command (0) | 2020.05.19 |
| 크롤링) Selenium을 이용하여 크롤링하기 (0) | 2020.05.11 |